This page is a mirror, as of June 4, 2003, of:
http://www.engelschall.com/pw/wt/loadbalance/article.html
Practical approaches for distributing HTTP traffic
B Y R A L F S . E N G E L S C H A L L
et us assume you are hosting a very popular website, say www.foo.dom, which receives 1.000.000 hits per day or approximately 1.000 hits per minute. This huge traffic requires a lot of resources on your webserver to really let you provide a good and reliable service: fast CPU (especially for CGI programs), lots of RAM (especially for parallel running HTTP daemon processes) and good I/O performance (especially for disk and network traffic).
The actual quality of service your webserver provides to the end user depends typically on two parameters: network transfer and server response time. The first one is mainly a matter of bandwidth of your Internet link while the latter one is actually a matter of the above mentioned resources.
But what to do when these resources are exhausted, i.e. your webserver is struggling against the heavy traffic? Although you now have a lot of options, only three practical ways are really useful:
So, from now on, say we have N such backend servers available, named wwwX.foo.dom (where X is between 1 and N), and want to use the cluster approach to solve our resource problem. Our goal now is to balance the traffic (addressed to www.foo.dom) onto these available servers wwwX.foo.dom in a way that the technical distribution is totally transparent to the end user. In other words: our website visitors still can use canonical URLs of the form http://www.foo.dom/bar/quux/ to reach the webcluster and are not directly confronted with the fact that their requests are served by more than one machines now. They never see the underlaying distribution. This is important both for backward compatibility and to avoid problems, for instance for bookmarking pages or the crash of a backend server. In short: The new webcluster should behave identical to the old single machine approach.
The DNS approach
The first solution we present is based on the Domain Name Service (DNS). Here we exploit the fact that the first step a browser has to perform to retrieve an URL http://www.foo.dom/bar/quux/ is to resolve the corresponding IP-address for www.foo.dom. This is done by a passive resolver library which itself calls a near DNS server which then actively iterates over the distributed DNS server hierarchy on the Internet until it reaches our own DNS server which finally gives out the IP-address. Now instead of giving out a static address for www.foo.dom we let our DNS server give out the address of one of the backend webservers. Which one depends on the scheme we want use for balancing the traffic and the technical possibilities we have available for this decision.
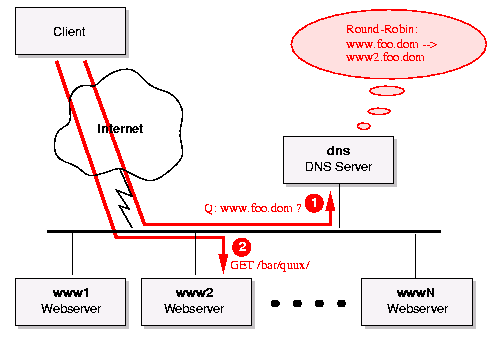
Figure 1: DNS-based Webserver Cluster The state-of-the-art in DNS server implementation is still BIND, the Berkeley Internet Name Daemon, which is currently developed and maintained by the Internet Software Consortium (ISC).
The key to our solution now is the fact that BIND provides a nifty but widely unknown feature called Round-Robin (RR). This feature lets us select and give out a particular IP-address from a pool of addresses when a DNS-request arrives while the selection pointer to this pool is moved one step further in the way of a circle. It is configured making www.foo.dom an alias which is mapped to wwwX.foo.dom by using multiple CNAME (canonical name) resource records:
www.foo.dom. IN CNAME www1.foo.dom. IN CNAME www2.foo.dom. IN CNAME www3.foo.dom. IN CNAME www4.foo.dom. IN CNAME www5.foo.dom. IN CNAME www6.foo.dom.This sounds perfectly in theory because this way we distribute the traffic totally equal onto the webcluster. But in practice we had to fight with the fact that DNS servers cache the resolved data at any point in the DNS hierarchy to both decrease the resolver traffic and to speedup resolving. This caching is controlled by a time-to-live (TTL) value which is appended to each information by our DNS server. It resides in the SOA (start of authority) resource record of the BIND zonefile in which the above snippet stays.Now we have a chicken and egg problem: When we set this TTL value too high, we decrease the DNS traffic on our Internet link, but let the other DNS servers cache our information too long which leads to bad HTTP traffic distribution over our webcluster. On the other hand, when we decrease this TTL value too much, we increase our DNS traffic and the request time for the visitor dramatically (because the other DNS servers expire our information faster, so had to resolve it more often), but we then have a better balancing of the HTTP traffic. The decision for the best TTL value is thus dependend of how good we really want the balancing and how much intermittent delays we think the visitor is accepting before he decides that the webcluster approach has reduced and not increased the quality of service. In practice a TTL of 1 hour has shown to be quite good.
But one problem remains: When we change the SOA resource record in the zonefile for foo.dom to achieve the effect for www.foo.dom we also change the TTL of all other entries in this zonefile, for instance ftp.foo.dom then also gets assigned the decreased TTL which increases the DNS traffic unnecessarily. So, to overcome this problem we had to use another trick: We move the Round-Robin feature for www.foo.dom into a separate zonefile which then only gets the decreased TTL. For the configuration we use a round-robin subdomain rr.foo.dom to achieve the effect. See Listing 1 to 3 for the final and complete BIND configuration.
LISTING ONE
LISTING TWO
LISTING THREE The Reverse Proxy approach
The described DNS-based approach is simple and elegant, but has some inherited drawbacks. Especially the caching of the DNS system and the simple round-robin decision scheme of BIND restricts its actual usefulness. For instance when one of the backend servers crash www.foo.dom is not available for at least the TTL we used for all visitors who's resolver has got the address of the crashed server. Even hitting the reload button in the browser doesn't work, because once a particular backend server was resolved, it remains the contact point for the particular vistor until the address information expires. Secondly the round-robin scheme treats all backend servers equal, for instance the backend servers cannot be selected dependend on the requesting URL. Perhaps we want to run very CPU-intensive jobs (e.g. CGI programs) only on a subset of the backend servers to avoid slowing down the serving of static data. So a different approach is needed which avoids these restrictions.We use a so-called Reverse Proxy, i.e. a HTTP Proxy Server operating in a direction which is reverse to the commonly known one. Usually a HTTP Proxy Server is logically used near the browsers or in front of them to bundle requests (when using a firewall) and to reduce bandwidth waste by performing data caching. Browsers call their proxy with the fully-qualified URL http://www.foo.dom/bar/quux/ and the proxy itself either forwards this request to parent proxies or finally requests the local URL /bar/quux/ from www.foo.dom. In other words, the proxy translates fully-qualified URLs either to fully-qualified URLs or local URLs. In contrast to this a Reverse Proxy masquerades as the final www.foo.dom server and translates the local URL back to a fully-qualified URL addressed to one of its backend servers.
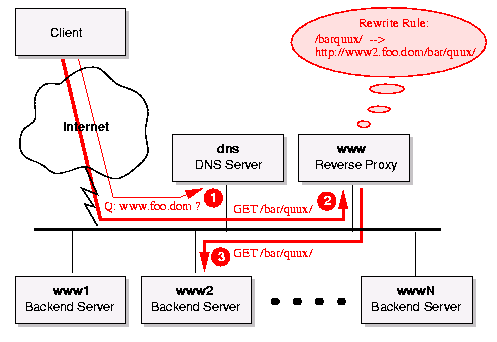
Figure 2: Reverse Proxy based Webserver Cluster As shown is figure 2 a Reverse Proxy resides side-by-side with the backend servers and visually (for the browser or the other proxies) acts as the final webserver. But instead of serving the request itself it on-the-fly determines a proper backend server, turns the request over to him and just forwards the response. No DNS tricks are needed here, i.e. www.foo.dom now actually resolves to the IP-address of the Reverse Proxy in the DNS. For security and/or speed considerations the backend servers can even be placed onto an own subnet which stays behind the Reverse Proxy (Figure 3). This way you separate the communication traffic between the Reverse Proxy and its backend servers and even avoid N officially assigned IP-addresses and DNS entries for the backend servers. Additionally you can even place the backend servers behind your company's firewall. In other words: A Reverse Proxy is a very elegant solution which provides maximum flexiblity for your network topology.
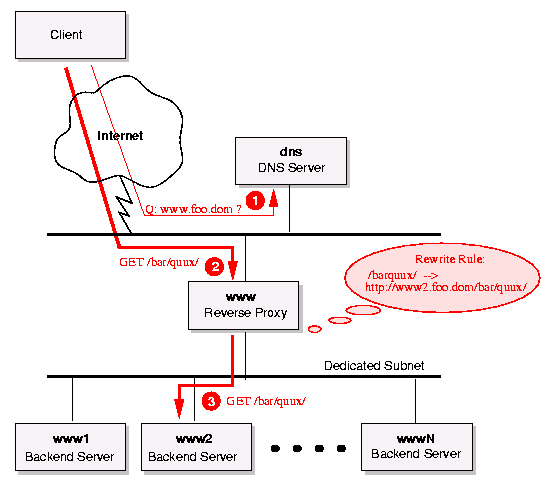
Figure 3: Reverse Proxy based Webserver Cluster with dedicated backend subnet Lets assume we have established this network/machine topology. What have we actually gained now? First we have a single point of access, the Reverse Proxy. This leads again to simplified traffic logging and monitoring of our website, although we are now using a webcluster instead of a single server. Secondly we now have complete control over the backend delegation scheme because its done locally in the Reverse Proxy for each request and not cached somewhere on the Internet. Additionally because the delegation scheme is now locally, a change of it immediately gets activated, for instance when one of the backend servers crash we just change the delegation configuration of the Reverse Proxy and the crashed backend no longer leads to errors for the visitors. After it is repaired we can activate it as simple as we deactivated it before.
Just one problem remains: Which hardware, software and configuration can be used to implement the Reverse Proxy? A lot of choices are possible, of course. Every one is more or less optimal to choose. There are both some dedicated Proxy software packages (e.g. Squid Internet Object Cache, Netscape's or Microsoft's Proxy Server, Sun's Netra Proxy Cache Server, etc.) and even hardware-based solutions (e.g. Cisco Systems' LocalDirector, Coyote Point Systems' Equalizer, etc.) available which can be used as a Reverse Proxy. We present a pragmatic and cheap but nevertheless high-performance solution here which is a very flexible all-in-one solution based on top of the popular Apache webserver.
The key to our solution is the following: Because we have to flexibly rewrite a mass of local URL requests to fully-qualified URL requests to the backend servers we need at least a scaleable server with a powerful URL rewriting engine and a HTTP proxy engine. Apache already provides these with its pre-forking process model and its modules mod_rewrite and mod_proxy. So the idea is to strip down the full-featured Apache to just this functionality and configure it accordingly to our requested functionality.
The exact functionality here was the problem. Although mod_rewrite is already a pervert module it was not pervert enough for us because it lacked the ability to do random selection. And after thinking long enough about the Reverse Proxy functionality we also noticed that mod_proxy lacked the possibility to divert HTTP responses back to itself. Because high-performance is a major requirement for a Reverse Proxy the only alternative would be Squid, the most popular dedicated Proxy. But this program also cannot be used as a Reverse Proxy trivially. So we decided to keep on the Apache track and just enhance it to allow the operation as a full-featured Reverse Proxy. At the time of writing the patches are considered to be committed into the official Apache sources for version 1.3b6, but currently only Apache 1.3b5 is available, so we first had to create the Apache binary out of the original sources plus the patches. Listing 4 shows you a script which automatically builds the binary. It can be received (together with the patches and the sample configuration) from http://www.engelschall.com/pw/wt/loadbalance/.
LISTING FOUR After running this script we have receive a binary named apache-rproxy which is a heavily stripped down Apache, but with the missing functionality added. So now we can start configuring it to act as our Reverse Proxy. Let us be concrete and assume we have a pool of exactly 6 backend webservers named www1.foo.dom to www6.foo.dom where www5.foo.dom and www6.foo.dom should be dedicated for running CPU-intensive jobs while www1.foo.dom to www4.foo.dom should mainly serve the static data. Between each of these two subsets of backend servers the traffic should be balanced.
LISTING FIVE So, lets start with the configuration of our available backend servers. We create a file named apache-rproxy.conf-servers as shown in listing 5. In line 9 under the key static we listed the servers which serve the static data and in line 13 under the key dynamic we listed the ones dedicated to dynamic data.
LISTING SIX 1 ## 2 ## apache-rproxy.conf -- Apache configuration for Reverse Proxy Usage 3 ## 4 5 # server type 6 ServerType standalone 7 Port 80 8 MinSpareServers <NOS> 9 StartServers <NOS> 10 MaxSpareServers <NOS> 11 MaxClients <NOS> 12 MaxRequestsPerChild 10000 13 14 # server operation parameters 15 KeepAlive on 16 MaxKeepAliveRequests 100 17 KeepAliveTimeout 15 18 Timeout 400 19 IdentityCheck off 20 HostnameLookups off 21 22 # paths to runtime files 23 PidFile /path/to/apache-rproxy.pid 24 LockFile /path/to/apache-rproxy.lock 25 ErrorLog /path/to/apache-rproxy.elog 26 CustomLog /path/to/apache-rproxy.dlog "%{%v/%T}t %h -> %{SERVER}e URL: %U" 27 28 # unused paths 29 ServerRoot /tmp 30 DocumentRoot /tmp 31 CacheRoot /tmp 32 RewriteLog /dev/null 33 TransferLog /dev/null 34 TypesConfig /dev/null 35 AccessConfig /dev/null 36 ResourceConfig /dev/null 37 38 # speed up and secure processing 39 <Directory /> 40 Options -FollowSymLinks -SymLinksIfOwnerMatch 41 AllowOverwrite None 42 </Directory> 43 44 # the status page for monitoring the reverse proxy 45 <Location /rproxy-status> 46 SetHandler server-status 47 </Location> 48 49 # enable the URL rewriting engine 50 RewriteEngine on 51 RewriteLogLevel 0 52 53 # define a rewriting map with value-lists where 54 # mod_rewrite randomly chooses a particular value 55 RewriteMap server rnd:/path/to/apache-rproxy.conf-servers 56 57 # make sure the status page is handled locally 58 # and make sure no one uses our proxy except ourself 59 RewriteRule ^/rproxy-status.* - [L] 60 RewriteRule ^(http|ftp)://.* - [F] 61 62 # now choose the possible servers for particular URL types 63 RewriteRule ^/(.*\.(cgi|shtml))$ to://${server:dynamic}/$1 [S=1] 64 RewriteRule ^/(.*)$ to://${server:static}/$1 65 66 # and delegate the generated URL by passing it 67 # through the proxy module 68 RewriteRule ^to://([^/]+)/(.*) http://$1/$2 [E=SERVER:$1,P,L] 69 70 # and make really sure all other stuff is forbidden 71 # when it should survive the above rules... 72 RewriteRule .* - [F] 73 74 # enable the Proxy module without caching 75 ProxyRequests on 76 NoCache * 77 78 # setup URL reverse mapping for redirect reponses 79 ProxyPassReverse / http://www1.foo.dom/ 80 ProxyPassReverse / http://www2.foo.dom/ 81 ProxyPassReverse / http://www3.foo.dom/ 82 ProxyPassReverse / http://www4.foo.dom/ 83 ProxyPassReverse / http://www5.foo.dom/ 84 ProxyPassReverse / http://www6.foo.dom/Additionally we need the actual Apache configuration file we run the apache-rproxy binary with. It is shown in listing 6. In lines 6-20 the runtime parameters are setup which we discuss later. In lines 23-26 we configure the auxiliary files Apache uses, but with a custom logfile which only shows the request delegation. In lines 29-36 we add some more directives to make Apache quiet on startup and to avoid runtime side-effects. In lines 38-42 we make our Reverse Proxy more secure and performant. Then we activate the online status monitor for our proxy through URL /rproxy-status in lines 45-47. Then comes the actual Reverse Proxy configuration. First we turn on the URL rewriting engine without logging in lines 50-51. Then we activate the above created apache-rproxy.conf-servers file by defining a rewriting map named servers which has a random subvalue post-processing enabled (the rnd-feature which was added by our patch). Then we have to make sure the status monitor is really handled locally and not by the backend servers and we have to make sure no one on the Internet exploits us by using our Reverse Proxy as a standard proxy.
Now comes the implementation of our delegation scheme. In line 63 we delegate all URLs to CGI programs and SSI pages to the servers under the key dynamic, which is either the server www5.foo.dom or www6.foo.dom. Which one is actually used is randomly chosen by mod_rewrite. All other URLs are then delegated in line 64 to the servers under the key static. Finally in line 68 we activate the delegation by passing the URL through the Apache proxy module mod_proxy while setting the environment variable SERVER to provide the logging module with complete information to write our delegation logfile we have configured in line 25. Then in line 72 we just make sure no URLs survive. Then in line 75-76 we activate mod_proxy as a plain Proxy without caching. And in lines 97-84 we configure mod_proxy as a reverse proxy by using the second feature we have patched into our Apache program: We force our Reverse Proxy to rewrite all URLs in Location headers the backend servers send on HTTP redirects to again use the Reverse Proxy. Because either the backends are not directly accessible or at least we want to really let all traffic flow over our Reverse Proxy and avoid by-passed traffic.
How much server processes we need?
Finally we have to calculate the number of server (NOS, see also the <NOS> placeholder in lines 8-11 of apache-rproxy.conf) and the amount of RAM in MB (MBR) we have to establish for our Reverse Proxy. To calculate these two values we need three input parameters: The maximum number of HTTP requests per minute (RPM) we expect, the avarage number of seconds a HTTP request needs to be completely served (SPR = seconds per request) and the maximum number of MB an apache-rproxy process needs to operate under the used operating system (SPS = server process size). Then the formulas are the following (assuming that because of lingering socket closes 20% of the servers are not always available and we conservatively only want to use %70 of the available memory for our Reverse Proxy and that we have RAM only in chunks of 16 MB modules available):
NOS = ceil(RPM * SPR * (1/60) * (100/80)) MBR = ceil((SPS * NOS * (100/70)) / 16) * 16So, for instance when we run our Reverse Proxy under FreeBSD, we see with the commands ps or top that each server process requires between 700 and 900 KB of RAM. So we have SPS = 0.9 MB. Because we have a traffic of approximately one thousend requests per minute we use RPM = 1.000. Finally we see with HTTP benchmarks or just by appreciating that processing time is between 0.5 and 4 seconds per request, so we use SPR = 2 seconds. With this numbers we then receive through the above formulas that we need NOS = ceil(1.000 * 2 * (1/60) * (100/80)) = 42 servers to start and that we have to make sure that our machine has at least MBR = ceil((0.9 * 42 * (100/70)) / 16) * 16 = 64 MB of total RAM installed.
(wt)
Ralf S. Engelschall is a computer science student in the 10th term at the Technische Universität München (TUM), Germany and a member of the developer teams of both the Apache Group and FreeBSD, Inc.
URL RESOURCES
BIND
http://www.isc.org/bind.html
ftp://ftp.isc.org/isc/bind/bind-4.9.6-REL.tar.gzApache
http://www.apache.org/
ftp://www.apache.org/apache/dist/apache_1.3b5.tar.gzApache Reverse Proxy patch
http://www.engelschall.com/pw/wt/balance/
http://www.engelschall.com/pw/wt/balance/dist/apache_1.3b5.patch-rproxy
Alternative Products
Software based solutions:
- Squid Internet Object Cache
http://squid.nlanr.net/Squid/- Netscape, Proxy Server
http://www.netscape.com/comprod/server_central/product/proxy/<- Microsoft, Proxy Server
http://www.microsoft.com/proxy/- Sun, Netra Proxy Cache Server
http://www.sun.com/products-n-solutions/hw/networking/netraproxy/Hardware based solutions:
- Cisco Systems, Local Director
http://www.cisco.com/univercd/cc/td/doc/prod_cat/pclocald.htm- Coyote Point Systems, Equalizer
http://www.coyotepoint.com/equalizer.shtml
Performance Tuning Apache under FreeBSD
At least when you are running Apache as your webserver on top of a FreeBSD box, you have a lot of possibilities to tune your system in order to achieve more performance.
Like on most operating systems the TCP/IP listen queue is often the first limit hit. It restricts the pending TCP requests. The second important parameter is the number of mbuf clusters which could be increased. Additionally you can increase the maximum number of allowed child processes and open file descriptors. So, for a heavily loaded machine increase these values in your kernel config via:
maxusers 256 options SOMAXCONN=256 options NMBCLUSTERS=4096 options CHILD_MAX=512 options OPEN_MAX=512Additionally you can try to use maximum optimization when building the kernel itself by using the GCC compiler flags-mpentium -O2 -fexpensive-optimizations -fomit-frame-pointeror even try to compile the kernel with the latest EGCS-based Pentium-GCC variant. But please be carefully here, always keep a working kernel at hand when doing such optimization tests.After tuning your operating system you can try to enhance the performance of Apache. In addition to the above kernel parameters you now first can increase the corresponding Apache parameters when building:
-DHARD_SERVER_LIMIT=256 -DDYNAMIC_MODULE_LIMIT=0 -DBUFFERED_LOGSAnd then you can tune the Apache configuration accordingly:MinSpareServers 256 StartServers 256 MaxSpareServers 256 MaxClients 256Additionally you can increase Apaches performance again by tuning some more parameters:MaxRequestsPerChild 10000 KeepAlive on KeepAliveTimeout 15 MaxKeepAliveRequests 64 Timeout 400 IdentityCheck off HostnameLookups off <Files ~ "\.(html|cgi)$> HostnameLookups on </Files> <Directory /> Options FollowSymLinks AllowOverride None </Directory>